Organic searches have become an integral part of our daily lives. Recent data shows that close to 30 percent of global web traffic is from online searches.
Search engines crawl and index billions of web content every day, ranking them in search results according to relevancy—how relevant they are to search queries—making them available to the public.
You could set up directives on how you wish search engines to crawl and show your web content to the public using the robot.txt file. This article takes you through everything you need to know about the robots.txt file.
Understanding the Robot.txt File
Search indexation begins with a simple search engine crawl. The robots.txt file, also known as the Robots Exclusion Protocol, instructs search bots on crawling a website—where and where not to go. Users often use the file to specify the pages search engines shouldn’t crawl.
When a search engine discovers a website through links or a sitemap, it opens the website’s robots.txt file to learn the page to crawl and the ones it shouldn’t. The crawler caches the robots.txt file to save it from opening it each time it visits the website. The cached file auto-refreshes several times each time, regularly keeping it updated.
The robots.txt is case sensitive and sits at the domain’s root, for example, www.domain.com/robots.txt.
Why a Robots.txt File Matters
Creating a robot.txt file for your website comes with many benefits; for instance, you could use it to manage your crawl budget. Search spiders often have a predetermined number of pages they can crawl on a website or the amount of time to spend on a website. If you manage a website with thousands of pages, you could block unimportant pages to maximize the crawl budget.
The other benefits of using a robots.txt file include:
- It helps web admins to control the web pages search engines can visit.
- The file gives users complete freedom to block specific bots from crawling their websites.
- The file helps prevent sensitive content from getting indexed.
- You could use it to block indexing of unnecessary files, like images, PDF and videos.
Improving Crawlability With Robots.txt File
Now, how do you improve your website crawlability with a robots.txt file? Of course, let’s find out.
Robots.txt Syntax
A robot file contains one or more blocks of directives to search engines, with the first line specifying the user agent—the name of the search spider to which you give the crawl directive.
Here’s how a basic robots.txt file looks:
Sitemap: https://yourdomain.com/sitemap_index.xml
User-agent: *
Disallow: /*?comments=all
Disallow: /wp-content/themes/user/js/script-comments.js
Disallow: /wp-comments-post.php
Disallow: /go/
User-agent: Googlebot
Disallow: /login
User-agent: bingbot
Disallow: /photo
The above robots.txt file contains three blocks of directives—the first directive is to all user-agents, the second directive is to Google crawlers, while the third is for Bing bots.
Here’s what the terms mean:
- Sitemap specifies the location of the website sitemap, which lists all the pages in a website, making it easier for crawlers to find and crawl them. You could also place the sitemap at the end of the robots.txt file.
- User-agent refers to the search bot(s) you wish to address the directives to, as explained earlier. Using asterisks (*) wildcard assigns the directive to all user-agents, but you could specify a user-agent using its correct name.
- Disallow directs the user-agents not to crawl the specified URL. You could leave the line empty to specify you’re not disallowing anything.
The Allow directive instructs the bots to crawl the specified URL, even if a prior instruction disallowed its directory, and here’s an example.
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
The robots.txt file blocks the wp-admin directory, which contains sensitive WordPress files including plugins and themes but permits the spiders to crawl and index the admin-ajax.php file in the directory.
The crawl-delay directive (crawl-delay: 10) tells the user-agents to wait for the specified number of seconds (for example, ten seconds) before crawling the page.
The directive tells search engines to change how frequently they crawl a page, helping you save bandwidth. Unfortunately, Google doesn’t recognize this directive again, but yahoo and Bing still do.
User-Agents Directives
Most search engines have different crawlers for different purposes. For example, some search engines have spiders for normal indexing, for images and videos, while some like Bing even have spiders for their ads program.
So, we’ve put together a table of all the common user-agents currently available today in alphabetical order.
Let’s take a look.
| S/N | Search Engine | Bots Type | User-agent |
| 1 | Baidu | General Indexing | baiduspider |
| 2 | Baidu | Image | baiduspider-image |
| 3 | Baidu | Mobile indexing | baiduspider-mobile |
| 4 | Baidu | News | baiduspider-news |
| 5 | Baidu | Videos | baiduspider-video |
| 6 | Bing | General | bingbot |
| 7 | Bing | General | msnbot |
| 8 | Bing | Images and Videos | msnbot-media |
| 9 | Bing | Ads | adidxbot |
| 10 | General | Googlebot | |
| 11 | Images | Googlebot-Image | |
| 12 | Mobile | Googlebot-Mobile | |
| 13 | News | Googlebot-News | |
| 14 | Video | Googlebot-Video | |
| 15 | AdSense | Mediapartners-Google | |
| 16 | Ads | AdsBot-Google | |
| 17 | Yahoo | General | slurp |
| 18 | Yandex | General | yandex |
The user-agents are case sensitive, so use the name correctly when setting up your robots.txt file.
Setting Up Crawl Directives
Let’s explore some of the ways you could use the robots.txt file to crawl your website seamlessly.
Crawling the Entire Website
You could set up the robots.txt file to allow all search bots to crawl and index your entire website. We don’t recommend this if you’ve private or sensitive files on your website.
However, to give this directive, add the below lines to your robots.txt file.
User-agent: *
Disallow:
But if you wish to allow only selected spiders to crawl and index the entire website, then specify the user agents, of course, one directive block per user-agent.
Blocking the entire Website
To prevent search engines from crawling and indexing your website, especially if you’re redesigning the website, you could block the entire website from getting indexed. Add this directive to your robots.txt file to get it done.
User-agent: *
Disallow: /
To prevent a bot from crawling your website, then specify the user-agent.
Blocking Selected Sections(s)
To block specific sections of the website, set up a disallow directive for the folder or page, and here’s an example.
User-agent: *
Disallow: /Videos
The directive blocks all spiders from crawling the video directory and everything in it. You could also use regular expressions like wildcard (*) and ($) to block groups of files. Unfortunately, most search engines don’t recognize the latter, including Google.
But here’s how to use regular expressions to block a group of files.
Disallow: images/*.jpg
Disallow: /*php$
The wildcard (*) blocks files in the image directory containing .jpg in its filename, while ($) blocks all files that end with .php.
Please do note that the disallow, allow, and user-agent values are case-sensitive. In our two examples above, search spiders will block:
- Videos directory but will not block /videos
- /images/beach.jpg but will crawl /images/beach.JPG
Robot.txt File Vs. NoIndex Tag
The robots.txt file directs spiders not to crawl a page but might not stop search engines from indexing the page if many websites link it. If a search engine discovers enough external links to the page, it will index the page without knowing its content, giving you a search result that looks thus:
![]()
But you could add the Noindex directive to your robots.txt file to prevent the files from showing up in the search result.
User-agent: *
Disallow: /Videos
Noindex: /Videos
You could also add a meta robots noindex tag to the page’s header to reliably prevent search engines from indexing it. If you use this option, avoid blocking the page with the robots.txt to enable the spiders to find the tag.
Generating a Robot.txt File
You can generate a robots.txt file for your website using some intuitive online tools, and here are just five:
- Ryte Robots.txt Generator
- SureOak Robots.txt File Generator
- SEOptimer Free Robots.txt Generator
- SEO PowerSuite Robots.txt Generator Tool
- SEOBook Robots.txt File Generator
Adding a Robots.txt File to Your Domain
You can add your newly created robots.txt to your domain via your account control panel, and here’s how.
Step 1: Access Your Account Control Panel
Access your account’s control panel by logging in to SPanel. Visit www.domain.com/spanel/login, replacing domain.com with your domain name.
Input your login credentials to log in.
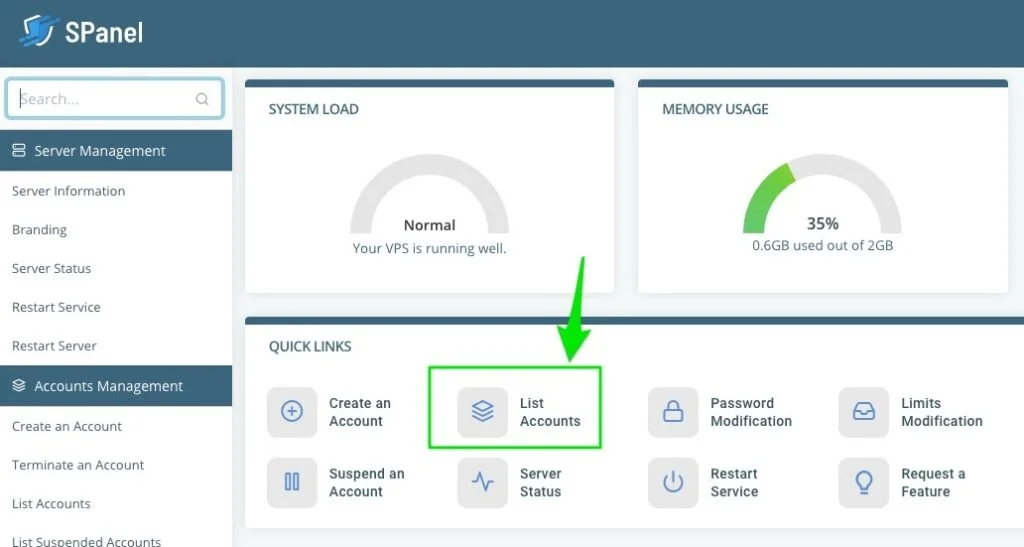
If you logged in as an admin, SPanel takes you to your admin dashboard, but user access logs you to the control panel. On the admin dashboard, scroll to QUICK LINKS and click List Accounts.
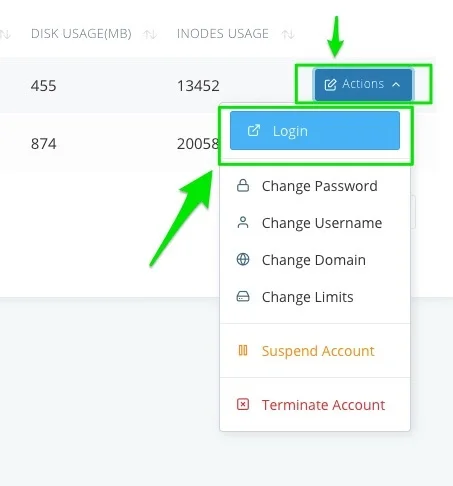
Click the Actions button of the account you wish to access its control panel and choose Login from the pull-up menu to get access.
Step 2: Open the File Manager
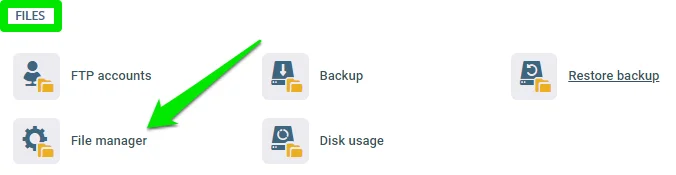
On the control panel, click File manager under the FILES section.
Open your website’s base or root directory. The root domain uses the public_html folder as its root directory.
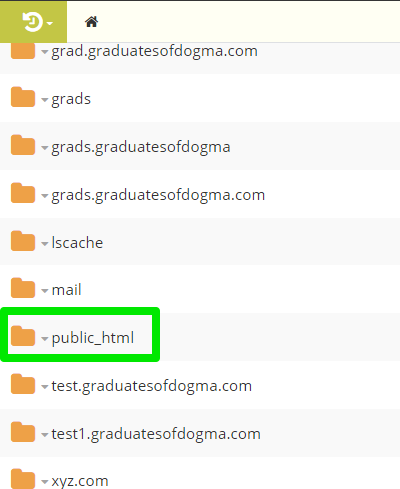
Step 3: Create the Robots.txt File
In the root directory, click the New File/Folder icon and select New File.
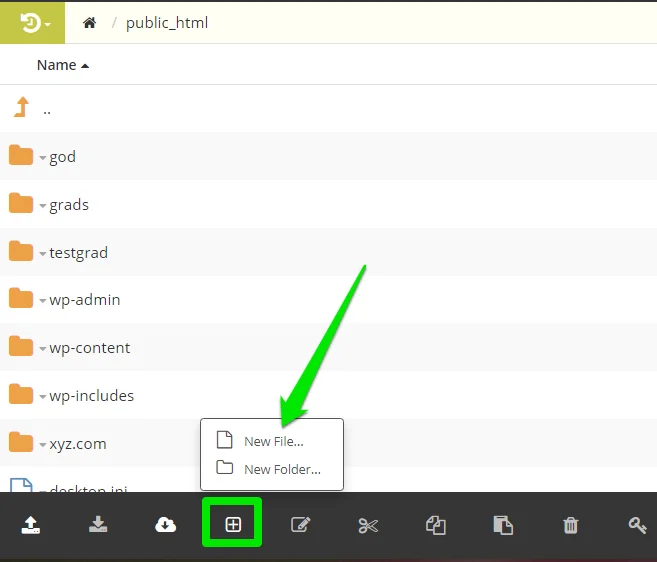
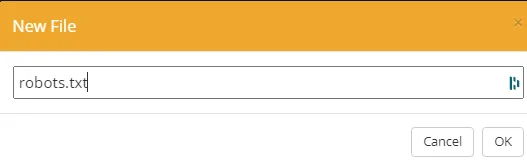
Name the new file robots.txt without caps and click OK to save
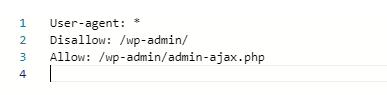
Write your crawl directives or Copy and paste them into the blank file and save.
That’s it.
Wrapping It Up
When you publish your robots.txt file, use the Google robots.txt Tester tool to validate the crawl directives to ensure you don’t mistakenly disallow pages you don’t intend to block.
And you can select any Google user-agent you wish to simulate. If you have questions related to robots.txt, do contact our support for quick assistance. We’re always available and ready to help.
